8.1. Chunks
8.2. PNG Signature
8.3. A Word on Color Representation
8.4. The Simplest PNG
8.5. PNG Image Types
8.5.1. Palette-Based
8.5.2. Palette-Based with Transparency
8.5.3. Grayscale
8.5.4. Grayscale with Transparency
8.5.5. Grayscale with Alpha Channel
8.5.6. RGB
8.5.7. RGB with Transparency
8.5.8. RGB with Alpha Channel
8.6. Interlacing and Progressive Display
The fundamental building block of PNG images is the chunk. With the exception of the first 8 bytes in the file (and we'll come back to those shortly), a PNG image consists of nothing but chunks.
Chunks were designed to be easily tested and manipulated by computer programs, easily detected by human eyes, and reasonably self-contained. Every chunk has the same structure: a 4-byte length (in ``big-endian'' format, as with all integer values in PNG streams), a 4-byte chunk type, between 0 and 2,147,483,647 bytes of chunk data, and a 4-byte cyclic redundancy check value (CRC). This is diagrammed in Figure 8-1.
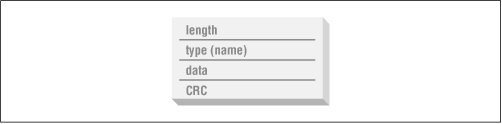 Figure 8-1: PNG chunk structure. |
The data field is straightforward; that's where the interesting bits (if any) go; specific content will be discussed later, as each chunk is described. The length field refers to the length of the data field alone, not the chunk type or CRC. The CRC, on the other hand, covers both the chunk-type field and the chunk data and is always present, even when there is no chunk data. Note that the combination of length fields and CRC values is already sufficient to check the basic integrity of a PNG file! The only missing information--not including the contents of the first 8 bytes in the file--is the exact algorithm (or ``polynomial'') used for the CRC. That turns out to be identical to the CRC used by gzip and many popular archiving programs; it is described in detail in Section 3.4 of the PNG Specification, Version 1.1, available from http://www.libpng.org/pub/png/pngdocs.html.
The chunk type is possibly the most unusual feature. It is specified as a sequence of binary values, which just happen to correspond to the upper- and lowercase ASCII letters used on virtually every computer in the Western, non-mainframe world. Since it is far more convenient (and readable) to speak in terms of text characters than numerical sequences, the remainder of this book will adopt the convention of referring to chunks by their ASCII names. Programmers of EBCDIC-based computers should take note of this and remember to use only the numerical values corresponding to the ASCII characters.
Chunk types (or names) are usually mnemonic, as in the case of the IHDR or image header chunk. In addition, however, each character in the name encodes a single bit of information that shows up in the capitalization of the character.[56] Thus IHDR and iHDR are two completely different chunk types, and a decoder that encounters an unrecognized chunk can nevertheless infer useful things about it. From left to right, the four extra bits are interpreted as follows:
[56] The ASCII character set was conveniently designed so that the case of a letter is always determined by bit 5. To put it another way, adding 32 to an uppercase character code gives you the code for its lowercase version.
The first character's case bit indicates whether the chunk is critical (uppercase) or ancillary; a decoder that doesn't recognize the chunk type can ignore it if it is ancillary, but it must warn the user that it cannot correctly display the image if it encounters an unknown critical chunk. The tEXt chunk, covered in Chapter 11, "PNG Options and Extensions", is an example of an ancillary chunk.
The second character indicates whether the chunk is public (uppercase) or private. Public chunks are those defined in the specification or registered as official, special-purpose types. But a company may wish to encode its own, application-specific information in a PNG file, and private chunks are one way to do that.
The case bit of the third character is reserved for use by future versions of the PNG specification. It must be uppercase for PNG 1.0 and 1.1 files, but a decoder encountering an unknown chunk with a lowercase third character should deal with it as with any other unknown chunk.
The last character's case bit is intended for image editors rather than simple viewers or other decoders. It indicates whether an editing program encountering an unknown ancillary chunk[57] can safely copy it into the new file (lowercase) or not (uppercase). If an unknown chunk is marked unsafe to copy, then it depends on the image data in some way. It must be omitted from the new image if any critical chunks have been modified in any way, including the addition of new ones or the reordering or deletion of existing ones. Note that if the program recognizes the chunk, it may choose to modify it appropriately and then copy it to the new file. Also note that unsafe-to-copy chunks may be copied to the new file if only ancillary chunks have been modified--again, including addition, deletion, and reordering--which implies that ancillary chunks cannot depend on other ancillary chunks.
[57] Since any decoder encountering an unknown critical chunk has no idea how the chunk modifies the image--only that it does so in a critical way--an editor cannot safely copy or omit the chunk in the new image.
So chunk names encode additional information that is primarily useful if the chunk is not recognized. The remainder of this book will be concerned with known chunks, but before we turn to those, there is one more component of PNG files that has to do with the unknown: the PNG file signature. As noted earlier, the first 8 bytes of the file are not, strictly speaking, a chunk.[58] They are a critical component of a PNG file, however, since they allow it to be identified as such regardless of filename. But the PNG signature bytes are more than a simple identifier code: they were cleverly designed to allow the most common types of file-transfer corruption to be detected. Web protocols these days typically ensure the correct transfer of binary files such as PNG images, but older transfer programs like the venerable command-line FTP (File Transfer Protocol) often default to text-mode or ``ASCII'' transfers. The unsuspecting user who transfers a PNG image or other binary file as text is practically guaranteed of destroying it. The same is true of the user who extracts a PNG file from a compressed archive in text mode or who emails it without some form of ``ASCII armor'' (such as MIME Base64 encoding or Unix uuencoding).
[58] They can be thought of as such, however, since their length is known (8 bytes), their position and purpose are known (beginning of the file; signature), and their CRC is implied (the 8 bytes are constant, so effectively they are their own CRC).
The 8-byte PNG file signature can detect this sort of problem because it simulates a text file in some respects. The 8 bytes are given in Table 8-1.
| Table 8-1. PNG Signature Bytes |
| Decimal Value |
ASCII Interpretation |
| 137 | A byte with its most significant bit set (``8-bit character'') |
| 80 | P |
| 78 | N |
| 71 | G |
| 13 | Carriage-return (CR) character, a.k.a. CTRL-M or ^M |
| 10 | Line-feed (LF) character, a.k.a. CTRL-J or ^J |
| 26 | CTRL-Z or ^Z |
| 10 | Line-feed (LF) character, a.k.a. CTRL-J or ^J |
The first byte is used to detect transmission over a 7-bit channel--for example, email transfer programs often strip the 8th bit, thus changing the PNG signature. The 2nd, 3rd, and 4th bytes simply spell ``PNG'' (in ASCII, that is). Bytes 5 and 6 are end-of-line characters for Macintosh and Unix, respectively, and the combination of the two is the standard line ending for DOS, Windows, and OS/2. Byte 7 (CTRL-Z) is the end-of-file character for DOS text files, which allows one to TYPE the PNG file under DOS-like operating systems and see only the acronym ``PNG'' preceded by one strange character, rather than page after page of gobbledygook. Byte 8 is another Unix end-of-line character.
Text-mode transfer of a PNG file from a DOS-like system to Unix will strip off the carriage return (byte 5); the reverse transfer will replace byte 8 with a CR/LF pair. Transfer to or from a Macintosh will strip off the line feeds or replace the carriage return with a line feed, respectively. Either way, the signature is altered, and in all likelihood the remainder of the file is irreversibly damaged.
Note that the 9th, 10th, and 11th bytes are guaranteed to be 0 (that is, the ASCII NUL character) by the fact that the first chunk is required to be IHDR, whose first 4 bytes are its length--a value that is currently 13 and, according to the spec, will never change. (Instead, ``new chunk types will be added to carry new information.'') The fact that the 0 bytes in the length come first is another benefit of the big-endian integer format, which stores the high-order bytes first. Since NUL bytes are also often stripped out by text-mode transfer protocols, the detection of damaged PNG files is even more robust than the signature alone would suggest.
Before we start putting chunks together, however, a brief interlude on the representation and terminology of color is useful. Color fundamentally refers to a property of light--namely, its wavelength. Each color in the rainbow, from red to purple, is a relatively pure strain of wavelengths of light, and none of these colors can be generated by adding together any of the others.[59] Furthermore, despite what our eyeballs would have us think, the spectrum does not end at deep purple; beyond that are the ultraviolet, X-ray, and gamma-ray domains. Nor does it end at dull red--smoke on the water glows in the infrared, if only we could see it, and still further down the spectrum are radio waves.[60] Each of these wavelength regions, from radio on up to gamma, is a color.
[59] Mathematically, this is known as orthogonality and is the basis for Fourier decomposition, among other things.
[60] It is probably not coincidence that the range of light visible to our water-filled orbs just happens to be the precise range of wavelengths that is not strongly absorbed by water.
So when someone refers to an RGB image--that is, containing only red, green, and blue values--as ``truecolor,'' what twisted logic lies behind such a claim? The answer lies not in physics but in physiology. Human eyes contain only three classes of color sensors, which trigger color sensations in the brain in ways that are not yet fully understood. One might guess that these sensors (the cones) are tuned to red, green, and blue light, but that turns out not to be the case, at least not directly. Instead, signals from the three types of cones are added and subtracted in various ways, apparently in more than one stage. The details are not especially important; what matters is that the end result is a set of only three signals going into the brain, corresponding to luminosity (or brightness), a red-versus-green intensity level, and a yellow-versus-blue level. In addition, the cones are not narrow-band sensors, but instead each responds to a broad range of wavelengths. The upshot is that the human visual system is relatively poor at analyzing colors, so feeding it different combinations of red, green, and blue light suffices to fool it into thinking it is seeing an entire spectrum. Keep in mind, however, that while true yellow and a combination of red and green may look identical to us, to spectrometers (or nonhuman eyes) they are quite different.
In fact, even printers ``see'' color differently. Since they employ pigments, which absorb light rather than emit it, the RGB color space that works so well for computer monitors is inappropriate. Instead, use a ``dual'' color space based on cyan, magenta, and yellow, or CMYK for short.[61] And in video processing, television, and the JPEG image format, yet another set of color spaces is popular: YUV, YIQ, and YCbCr, all of which represent light as an intensity value (Y) and a pair of orthogonal color vectors (U and V, or I and Q, or Cb and Cr). All of these color spaces are beyond the scope of this book, but note that every single one of them has its basis in human physiology. Indeed, if YUV and its brethren sound quite a lot like the set of three signals going into the brain that I just discussed, rest assured that it's not coincidence. Not a single color space in common use today truly represents the full continuum of physical color.
[61] The K is for black. Since black is the preferred color for a huge class of printed material, including text, it is more efficient and considerably cheaper to use a single pigment for it than always to be mixing the other three. Some printing systems actually use five, six, or even seven distinct pigments.
Finally, note that image files may represent the appearance of a scene not only as a self-contained item, but also in reference to a background or to other images or text. In particular, transparency information is often desirable. The simplest approach to transparency in computer graphics is to mark a particular color as transparent, but more complex applications will generally require a completely separate channel of information. This is known as an alpha channel (or sometimes an alpha mask) and enables the use of partial transparency, such as is often used in television overlays. In the text that follows, I will refer to an RGB image with an alpha channel as an RGBA image. PNG adheres to the usual convention that alpha represents opacity; that is, an alpha value of 0 is fully transparent, and the maximum value for the pixel depth is completely opaque. PNG also uses only unassociated alpha, wherein the actual gray or color values are stored unchanged and are only affected by the alpha channel at display time. The alternative is associated or premultiplied alpha, in which the pixel values are effectively precomposited against a black background; although this allows slightly faster software compositing, it amounts to a lossy transformation of the image data and was therefore rejected in the design of PNG.
We've looked at the fine details of a PNG file--the subatomic structure, if you will--so let us turn now to a few of the basic atoms (chunks) that will allow us to create a complete ``molecule,'' or valid Portable Network Graphics file. The simplest possible PNG file, diagrammed in Figure 8-2, is composed of the PNG signature and only three chunk types: the image header chunk, IHDR; the image data chunk, IDAT; and the end-of-image chunk, IEND. IHDR must be the first chunk in a PNG image, and it includes all of the details about the type of the image: its height and width, pixel depth, compression and filtering methods, interlacing method, whether it has an alpha (transparency) channel, and whether it's a truecolor, grayscale, or colormapped (palette) image. Not all combinations of image types are valid, however, and much of the remainder of this chapter will be devoted to a discussion of what is allowed.
 Figure 8-2: Layout of the simplest PNG. |
IDAT contains all of the image's compressed pixel data. Although single IDATs are perfectly valid as long as they contain no more than 2 gigabytes of compressed data, in most images the compressed data is split into several IDAT chunks for greater robustness. Since the chunk's CRC is at the end, a streaming application that encounters a large IDAT can either force the user to wait until the complete chunk arrives before displaying anything, or it can begin displaying the image without knowing if it's valid. In the latter case, if the IDAT happens to be damaged, the user will see garbage on the display. (Since the image dimensions were already read from a previously CRC-checked chunk, in theory the garbage will be restricted to the region belonging to the image.) Fortunately, small IDAT chunks are by far the most common, particularly in sizes of 8 or 32 kilobytes.
IEND is the simplest chunk of all; it contains no data, just indicates that there are no more chunks in the image. IEND is primarily useful when the PNG image is being transferred over the network as a stream, especially when it is part of a larger MNG stream (Chapter 12, "Multiple-Image Network Graphics"). And it serves as one more check that the PNG file is complete and internally self-consistent.
These three chunk types are sufficient to build truecolor and grayscale PNG files, with or without an alpha channel, but palette-based images require one more: PLTE, the palette chunk. PLTE simply contains a sequence of red, green, and blue values, where a value of 0 is black and 255 is full intensity; anywhere from 1 to 256 RGB triplets are allowed, depending on the pixel depth of the image. (That is, for a 4-bit image, no more than 16 palette entries are allowed.) The PLTE chunk must come before the first IDAT chunk; the structure of a colormapped PNG is shown in Figure 8-3.
 Figure 8-3: Layout of the second-simplest PNG. |
I noted earlier that not all possible combinations of PNG image types and features are allowed by the specification. Let's take a closer look at the basic types and their features.
Palette-based images, also known as colormapped or index-color images, use the PLTE chunk and are supported in four pixel depths: 1, 2, 4, and 8 bits, corresponding to a maximum of 2, 4, 16, or 256 palette entries. Unlike GIF images, however, fewer than the maximum number of entries may be present. On the other hand, GIF does support pixel depths of 3, 5, 6, and 7 bits; 6-bit (64-color) images, in particular, are common on the World Wide Web.
TIFF also supports palette images, but baseline TIFF allows only 4- and 8-bit pixel depths. Perhaps a more useful comparison is with the superset of baseline TIFF that is supported by Sam Leffler's free libtiff, which has become the software industry's unofficial standard for TIFF decoding. libtiff supports palette bit depths of 1, 2, 4, 8, and 16 bits. Unlike PNG and GIF, however, the TIFF palette always uses 16-bit integers for each red, green, and blue value, and as with GIF, all 2bit depth entries must be present in the file. Nor is there any provision for compression of the palette data--so a 16-bit TIFF palette would require 384 KB all by itself.
The PNG spec forbids the use of a full alpha channel with palette-based images, but it does allow ``cheap alpha'' via the transparency chunk, tRNS. As its name implies--the first letter is lowercase--tRNS is an ancillary chunk, which means the image is still viewable even if the decoder somehow fails to recognize the chunk.[62] The structure of tRNS depends on the image type, but for palette-based images it is exactly analogous to the PLTE chunk. It may contain as many transparency entries as there are palette entries (more than that would not make any sense) or as few as one, and it must come after PLTE and before the first IDAT. In effect, it transforms the palette from an RGB lookup table to an RGBA table, which implies a potential factor-of-four savings in file size over a full 32-bit RGBA image. The icicle image used as a basis for Figure C-1 in the color insert is an RGBA-palette image; it is ``only'' 3.85 times smaller than the 32-bit original due to dithering (which hurts compression).
[62] Once again, the distinction between critical and ancillary chunks is largely irrelevant for chunks defined in the specification, since presumably they are known by all decoders. But even the names of standard chunks were chosen in accordance with the rules, as if they might be encountered by a particularly simple-minded PNG decoder. In fact, this was done in order to test the chunk-naming rules themselves: would a decoder that relied only on them behave sensibly? The answer was ``yes.''
By comparison, GIF supports only binary transparency, wherein a single palette color is marked as completely transparent, while all others are fully opaque. GIF has a tiny advantage in that the transparent entry can live anywhere in the palette, whereas a single PNG transparency entry should come first--all tRNS entries before the transparent one must exist and must have the value 255 (fully opaque), which would be redundant and therefore a waste of space. But the code necessary to rearrange the palette so that all non-opaque entries come before any opaque ones is simple to write, and the benefits of PNG's more flexible transparency scheme far outweigh this minor drawback.
The TIFF format supports at least three kinds of transparency information, two involving an interleaved alpha channel (extra samples) and the third involving a completely separate subimage (or subfile) that is used as a bilevel transparency mask. Baseline TIFF does not require support for any of them, but libtiff supports the two interleaved flavors directly, and could probably be manhandled into some level of support for the subfile approach, although the transparency mask is ``typically at a higher resolution than the main image if the main image is grayscale or color,'' according to the TIFF 6.0 specification. On the other hand, with the possible exception of user-designed TIFF tags, there is no support at all for ``cheap alpha,'' i.e., marking one or more palette entries as partially or completely transparent.
PNG grayscale images support the widest range of pixel depths of any image type. Depths of 1, 2, 4, 8, and 16 bits are supported, covering everything from simple black-and-white scans to full-depth medical and raw astronomical images.[63]
[63] Calibrated astronomical image data is usually stored as 32-bit or 64-bit floating-point values, and some raw data is represented as 32-bit integers. Neither format is directly supported by PNG, although one could, in principle, design an ancillary chunk to hold the proper conversion information. Conversion of data with more than 16 bits of dynamic range would be a lossy transformation, however--at least, barring the abuse of PNG's alpha channel or RGB capabilities.
There is no direct comparison with GIF images, although it is certainly possible to store grayscale data in a palette image for both GIF and PNG. The only place a gray palette is commonly distinguished from a regular color one, however, is in VRML97 texture maps. Baseline TIFF images, on the other hand, support 1-bit ``bilevel'' and 4- and 8-bit grayscale depths. Nonbaseline TIFF allows arbitrary bit depths, but libtiff accepts only 1-, 2-, 4-, 8-, and 16-bit images. TIFF also supports an inverted grayscale, wherein 0 represents white and the maximum pixel value represents black.
The most common form of JPEG (the one that uses ``lossy'' compression, in which some information in the image is thrown away) likewise supports grayscale images in depths of 8 and 12 bits. In addition, there are two variants that use truly lossless compression and support any depth from 2 to 16 bits: the traditional version, known simply as ``lossless JPEG,'' and an upcoming second-generation flavor called ``JPEG-LS.''[64] But the first is extremely rare, and is supported by almost no one, despite having been standardized years ago, and the second is also currently unsupported (although that is to be expected for a new format). Lossy JPEG is very well supported, thanks largely to the Independent JPEG Group's free libjpeg (which, like libtiff, has become the de facto standard for JPEG encoding and decoding)--but, of course, it's lossy. Note that libjpeg can be compiled to support either 8-bit or 12-bit JPEG, but not both at the same time. Thus, from a practical standpoint, only 8-bit, lossy grayscale is supported.
[64] Be aware that even at the highest quality settings, the common form of JPEG is never lossless, regardless of whether the setting claims 100% or something similar.
PNG supports two kinds of transparency with grayscale and RGB images. The first is a palette-style ``cheap transparency,'' in which a single color or gray value is marked as being fully transparent. I noted earlier that the structure of tRNS depends on the image type; for grayscale images of any pixel depth, the chunk contains a 2-byte, unscaled gray value--that is, the maximum allowed value is still 2bit depth-1, even though it is stored as a 16-bit integer. This approach is very similar to GIF-style transparency in palette images and incurs only 14 bytes overhead in file size. There is no corresponding TIFF image type, and standard JPEG does not support any transparency.
The second kind of transparency supported by grayscale images is an alpha channel. This is a more expensive approach in terms of file size--for grayscale, it doubles the number of image bytes--but it allows the user much greater freedom in setting individual pixels to particular levels of partial transparency. Only 8-bit and 16-bit grayscale images may have an alpha channel, which must match the bit depth of the gray channel.
The full TIFF specification supports two kinds of interleaved ``extra samples'' for transparency: associated and unassociated alpha (though not at the same time). Unlike PNG, TIFF's alpha channel may be of a different bit depth from the main image data--in fact, every channel in a TIFF image may have an arbitrary depth. TIFF also offers the explicit possibility of treating a ``subfile,'' or secondary image within the file, as a transparency mask, though such masks are only 1 bit deep, and therefore support only completely opaque or completely transparent pixels.
Baseline TIFF does not require support for any of this, however. Current versions of libtiff can read an interleaved alpha channel as generic ``extra samples,'' but it is up to the application to interpret the samples correctly. The library does not support images with channels of different depths, and although it could be manipulated into reading a secondary grayscale subfile (which the application could interpret as a full alpha channel), that would be a user-defined extension--i.e., specific to the application and not supported by any other software.
As I just noted, standard JPEG (by which I mean the common JPEG File Interchange Format, or JFIF files) has no provision for transparency. The JPEG standard itself does allow extra channels, one of which could be treated as an alpha channel, but this would be fairly pointless. Not only would it require one to use a non-standard, unsupported file format for storage, there would also tend to be visual artifacts, since lossy JPEG is not well suited to the types of alpha masks one typically finds (unless the mask's quality setting were boosted considerably, at a cost in file size). But see Chapter 12, "Multiple-Image Network Graphics" for details on a MNG subformat called JNG that combines a lossy JPEG image in JFIF format with a PNG-style, lossless alpha channel.
RGB (truecolor) PNGs, like grayscale with alpha, are supported in only two depths: 8 and 16 bits per sample, corresponding to 24 and 48 bits per pixel. This is the image type most commonly used by image-editing applications like Adobe Photoshop. Note that pixels are stored in RGB order. (BGR is the other popular format, especially on Windows-based systems.)
Truecolor PNG images may also include a palette (PLTE) chunk, though the specialized suggested-palette (sPLT) chunk described in Chapter 11, "PNG Options and Extensions" is often more appropriate. But if present, the palette encodes a suggested set of colors to which the image may be quantized if the decoder cannot display in truecolor; the suggestion is presumed to be a good one, so decoders are encouraged to use it if they can. Of course, multi-image viewers such as web browsers often resort to a fixed palette for simplicity and rendering speed.
Baseline TIFF requires support only for 24-bit RGB, but libtiff supports 1, 2, 4, 8, and 16 bits per sample. Ordinary JPEG stores only 24-bit RGB,[65] though 36-bit RGB is possible with the seldom-supported 12-bit extension. The also seldom-supported lossless flavor of JPEG can, in theory, store any sample depth from 2 to 16 bits, thus 6 to 48 bits per RGB pixel.
[65] Technically, color JPEGs are almost always encoded internally in the YCbCr color space and converted to or from RGB by the decoder or encoder software.
As mentioned previously, PNG supports cheap transparency in RGB images via the tRNS chunk. The format is similar to that for grayscale images, except now the chunk contains three unscaled, 16-bit values (red, green, and blue), and the corresponding RGB pixel is treated as fully transparent. This option adds only 18 bytes to the image, and there are no corresponding TIFF or JPEG image types.
Finally, we have truecolor images with an alpha channel, also known as the RGBA image type. As with RGB and gray+alpha, PNG supports 8 and 16 bits per sample for RGBA or 32 and 64 bits per pixel, respectively. Pixels are always stored in RGBA order, and the alpha channel is not premultiplied.
The use of PLTE for a suggested quantization palette is allowed here as well, but note that since the tRNS chunk is prohibited in RGBA images, the suggested palette can only encode a recommended quantization for the RGB data or for the RGBA data composited against the image's background color (see the discussion of bKGD in Chapter 11, "PNG Options and Extensions"), not for the raw RGBA data. Disallowing tRNS is arguably an unnecessary restriction in the PNG specification; while a suggested RGBA palette would not necessarily be useful when compositing the image against a varied background (the different background pixel values would likely mix with the foreground pixels to form more than 256 colors), it would be helpful for cases where the background is a solid color. In fact, this restriction was recognized and addressed by an extension to the specification approved late in 1996: the suggested-palette chunk, sPLT, which is discussed in Chapter 11, "PNG Options and Extensions".
Although baseline TIFF does not require support for an alpha channel, libtiff supports RGBA images with 1, 2, 4, 8, or 16 bits per sample; both associated and unassociated alpha channels are supported. JPEG has no direct support for alpha transparency, but MNG offers a way around that (see Chapter 12, "Multiple-Image Network Graphics").
We'll wrap up our look at the basic elements of Portable Network Graphics images with a quick consideration of progressive rendering and interlacing. Most computer users these days are familiar with the World Wide Web and the method by which modern browsers present pages. As a rule, the textual part of a web page is displayed first, since it is transmitted as part of the page; then images are displayed, with each one rendered as it comes across the network. Ordinary images are simply painted from the top down, a few lines at a time; this is the most basic form of progressive display.
Some images, however, are in a format that allows them to be rendered as an overall, low-resolution image first, followed by one or more passes that refine it until the complete, full-resolution image is displayed. For GIF and PNG images this is known as interlacing. GIF's approach has four passes and is based on complete rows of the image, making it a one-dimensional method. First every eighth row is displayed; then every eighth row is displayed again, only this time offset by four rows from the initial pass. The third pass consists of every fourth row, and the final pass includes every other row (half of the image).
PNG's interlacing method, on the other hand, is a two-dimensional scheme with seven passes, known as the Adam7 method (after its inventor, Adam Costello). If one imagines the image being broken up into 8 × 8-pixel tiles, then the first pass consists of the upper left pixel in each tile--that is, every eighth pixel, both vertically and horizontally. The second pass also consists of every eighth pixel, but offset four pixels to the right.
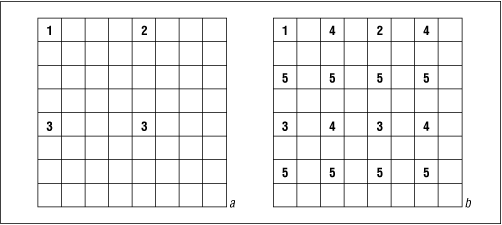 Figure 8-4: Schematic of an 8 × 8 tile (a) after the third pass and (b) after the fifth pass. |
The third pass consists of two pixels per tile, offset by four rows from the first two pixels (see Figure 8-4a). The fourth pass contains four pixels in each tile, offset two columns to the right of each of the first four pixels, and the fifth pass contains eight pixels, offset two rows downward (see Figure 8-4b). The sixth pass fills in the remaining pixels on the odd rows (if the image is numbered starting with row one), and the seventh pass contains all of the pixels for the even rows. Note that, although I've described the method in terms of 8 × 8 tiles, pixels for any given pass are stored as complete rows, not as tiled groups. For example, the fifth pass consists of every other pixel in the entire third row of the image, followed by every other pixel in the seventh row, and so on.
The primary benefit of PNG's two-dimensional interlacing over GIF's one-dimensional scheme is that one can view a crude approximation of the entire image roughly eight times as fast.[66] That is, PNG's first pass consists of one sixty-fourth of the image pixels, whereas GIF's first pass consists of one-eighth of the data. Suppose one were to save a palette image as both an interlaced GIF and an interlaced PNG. Assuming the compression ratio and download speeds were identical for the two files, the PNG image would have completed its fourth pass as the GIF image completed its first. But most browsers that support progressive display do so by replicating pixels to fill in the areas that haven't arrived yet. For the PNG image, that means each pixel at this stage represents a 2 × 4 block, whereas each GIF pixel represents a 1 × 8 strip. In other words, GIF pixels have an 8-to-1 aspect ratio, whereas PNG pixels are 2-to-1. At the end of the next pass for each format (GIF's second pass, PNG's fifth; one-quarter of the image in both cases), the PNG pixels are square 2 × 2 blocks, while the GIF pixels are still stretched, now as 1 × 4 strips. In practical terms, features in the PNG image--particularly embedded text--are much more recognizable than in the GIF image. In fact, readability testing suggests that text of any given size is legible roughly twice as fast with PNG's interlacing method.
[66] As I (foot)noted in Chapter 1, "An Introduction to PNG", this implicitly assumes that one-eighth of the compressed data corresponds to one-eighth of the uncompressed (image) data, which is not quite accurate. The difference is likely to be small in most cases, however. I'll discuss this further in Chapter 9, "Compression and Filtering".
JPEG also supports a form of progressive display, but it is not interlacing in the usual sense of reordering the pixels spatially. Rather, it involves reordering the frequency components that make up a JPEG image, first displaying the low-frequency ones and working up to the highest frequency band; this is known as spectral selection. In addition, progressive JPEG can transmit the most significant bits of each frequency component earlier than the less significant ones, a feature known as successive approximation that is very nearly the same as turning up the JPEG quality setting with each scan. The two approaches can be used separately, but in practice they are almost always used in combination. Because JPEG operates on 8 × 8 blocks of pixels, progressive JPEG bears a strong resemblance to interlaced PNG during the early stages of display, though it tends to have a softer, fuzzier look due to the initial lack of high-frequency components (which is often deliberately enhanced by smoothing in the decoder). This is visible in Figures C-4a and C-4b in the color insert, which represent the second pass of a progressive JPEG image (26% of the compressed data), both unsmoothed and smoothed. Note in particular the blockiness in the shadowed interior of the box and the ``colored outside the lines'' appearance around the child's arms and hands; the first effect is completely eliminated in the smoothed version, and the second is greatly reduced. JPEG's first pass is actually more accurate than PNG's, however, since the low-frequency band for each 8 × 8 pixel block represents an average for all 64 pixels, whereas each 8 × 8 block in PNG's first pass is represented by a single pixel, usually in the upper left corner of the displayed block. By its fifth pass, which represents only 40% of the compressed data, the progressive JPEG version of this image (Figure C-4c) is noticeably sharper and more accurate than all but the final pass of the PNG version. Keep in mind also that, since the PNG is lossless and therefore 11 times as large as the JPEG, 40% of the compressed JPEG data is equivalent to only 3.5% of the PNG data, which corresponds to the beginning of PNG's third pass. This only emphasizes the point made previously: for non-transparent, photographic images on the Web, use JPEG.
Note that smoothing could be applied to the early passes of interlaced PNGs and GIFs, as well; tests suggest that this looks better for photographic images but maybe not as good for simple graphics. (On the other hand, recall that smoothing did seem to enhance the readability of early interlace passes in Figure 1-4.) As for representing blocks by the pixel in the upper left corner, it would be possible to replicate each pixel so that the original would lie roughly at the center of its clones, as long as some care were taken near the edges of the image. This would prevent the apparent shift in some features as later passes are displayed. But neither smoothing nor centered pixel replication is currently supported by the PNG reference library, libpng, as of version 1.0.3.
It is worth noting that TIFF can also support a kind of interlacing, although like everything about TIFF, it is much more arbitrary than either GIF's or PNG's method. Baseline TIFF includes the concept of strips, each of which may include one or more rows of image data though the number of rows per strip is constant. A list of offsets to each strip is embedded within the image, so in principle one could make each strip a row and do GIF-style line interlacing with any ordering one chose. But since TIFF's structure is fundamentally random access in nature, this approach would only work if one imposed certain restrictions on the locations of its internal directory, list of strip offsets, and actual strip data--that is, one would need to define a particular subformat of TIFF.
In addition, libtiff supports a TIFF extension called tiles, in which the image data is organized into rectangular regions instead of strips. Since the tile size can be arbitrary, one could define it to be 1 × 1 and then duplicate PNG's Adam7 interlacing scheme manually--or even extend it to 9, 11, or more passes. However, since every tile must have a corresponding offset in the TIFF image directory, doing something like this would at least double or triple the image size. Also, TIFF's compression methods apply only to individual strips or tiles, so there would be no real possibility of compression aside from reusing tiles in more than one location (that is, by having multiple tile offsets point at the same data). And, as with the strip approach, this would require restrictions on the internal layout of the file. Nevertheless, the capability does exist, at least theoretically.